This post is going to discuss the relationships between, and meanings of:
Character sets (CHARSETs) for example “ISO-8859-1”
Encodings for characters (eg. single byte, multi byte, wide character)
Code charts
Unicode
How it all fits together
Disclaimer
This is a somewhat simplified discussion about the issues. The issue of code pages and encoding is rather complex. For example, the very fact that there is a code page “CP437” (mentioned below) would seem to imply that there are at least 436 other ones! Also, under Unicode not every code point is a “printable” character — some code points modify adjacent characters (like add an accent).
Also right-to-left display/printing is not covered.
For more information see the “Further Reading” at the bottom of this page.
Character encoding
History
Early encoding systems
In the olden days, computers were initially used for numbers. For example, initially the Army used them for calculations for where to aim a cannon in order for the shell to land where they wanted it to. Also, they were used for calculations of mathematical tables (like logarithms) to avoid human error.
Fairly soon it was realized that numbers could also represent letters. An early application of computers was cracking the Enigma cypher machine. In order to have a number represent a letter (eg. A, B, C …) the designers would arbitrarily assign a value, or code, to each letter. For example:
Letter
Code
A
1
B
2
C
3
D
4
…
…
Z
26
space
27
comma
28
period
29
…
…
0
40
1
41
2
42
3
43
…
…
Using this encoding system we might encode the word “BAD” as 2,1,4.
The exact system wasn’t important as long as it was consistent. For example, an input device like a teletype would need to send the number 1 if you typed “A”, and a printer would need to print “A” if you sent it the number 1 (using the above scheme).
Note that this sequence of numbers only represents “BAD” if we know the encoding scheme.
We might have chosen to put the number digits first, in which case 2,1,4 would represent something else entirely. For example:
Letter
Code
0
0
1
1
2
2
3
3
…
…
9
9
A
10
B
11
C
12
D
13
…
…
Z
35
space
36
comma
37
period
38
…
…
In this (hypothetical) different scheme “BAD” would be 11,10,13. On the other hand 2,1,4 would represent “214”.
The importance of knowing the encoding scheme persists to this day. If you have a file on disk, a web page, or an email, the bytes in the document are meaningless without knowing which encoding system was used to encode it.
Typically these days in countries like Australia, Britain, and the United States the encoding scheme would be a variant of ASCII such as ISO-8859-1 or Windows-1252 (described later), so most people don’t worry about it too much, in particular if they are not using characters with the high-order bit set.
High-order bits
In computer terminology the high-order bit in a memory field is the one with the highest value. In an 8-bit field this is the bit with the value 128. The low-order bit has a value of 1. For example, the letter “A” in ASCII (in decimal: 65, in hex: 0x41, in binary: 0100 0001) looks like this:
The “left-hand” bit is the high-order bit. Thus in this example the decimal number 65 is obtained as:
(1 × 64) + (1 × 1) = 65
Squeezing data into 6 bits
On early computers I worked on, designers worked hard to save RAM, which was incredibly expensive in those days.
For example, on the NCR 315 computer, memory was addressed in 12-bit “slabs” (syllables). One slab could represent 3 × 4-bit digits (for numbers) or 2 × 6-bit characters (for storing letters), as follows:
4 bits for digits has 24 (16) permutations, which is enough for BCD (binary-coded decimal) representation.
I don’t remember exactly what encoding system they used for characters, but clearly a letter had to be represented by a number in the range 0 to 63 (which is 26 combinations).
There wasn’t room to hold lower-case letters, so everything was in upper-case in those days. (It would take 2×26 characters for upper and lower-case Latin letters, plus 10 for digits, plus you would need a dozen or so for punctuation, which adds up to more than 64 combinations)
In addition to the problems of storing lower-case letters into 6 bits, the printers used in those days often did not support lower-case characters.
EBCDIC
In 1963 IBM invented the EBCDIC (Extended Binary Coded Decimal Interchange Code) encoding system. This encoded various characters into an 8-bit byte as follows:
There are various versions of EBCDIC around. The chart above may not accurately represent all of them, however it shows the idea.
An interesting feature (and a very frustrating one for programmers) was the non-sequential arrangement of characters. For example letters are broken up into groups (“ABCDEFGHI” … other stuff … “JKLMNOPQRS” … other stuff … “STUVWXYZ”). This meant that testing if a character in a file or user input was alphabetic or not was not as simple as writing something like:
if (x >= 'A' && x <= 'Z')
{
// is alphabetic
}
else
{
// is not alphabetic
}
This can be explained a bit by looking at a punched card, which were used very often in those days:
The letters (shown on the top of the card) were in groups of 9 overpunched with a “zone” punch at the top. So you can see that “A” is top zone punch plus “1”, “B” is top zone punch plus “2” and so on. The sequences in EBCDIC mirror the batches of letters in each zone.
How to read the code charts on this page
ASCII
At about the same time EBCDIC was being developed, ASCII (American Standard Code for Information Interchange) was also under development (the standard was released in 1963).
The ASCII code was a 7-bit code (so the high-order bit was not used). It had a more sequential arrangement (all the upper-case letters were contiguous, for example).
Fun fact!
Did you ever wonder why the control code “DEL” has a value of 0x7F?. In binary that is all 7 bits on (“1111111” assuming a 7-bit code).
Well, in the olden days data was input using punched paper tape, which came in long reels.
Now the problem with a long reel of tape is, that if you make a typing mistake, it is committed into holes (you can’t un-punch tape!). So, the way they dealt with errors was you backspaced one sprocket, and then typed “DEL” which punched all of the available holes, like this (shaded box):
The significance of this was that no matter what the original character was, punching all of the holes on top of it was guaranteed to give a character with all the holes punched.
The reader program was designed to just ignore the DEL character when it came across it. Presumably you punched the correct character directly after the incorrect one (the DEL character) or if that wasn’t practical you might “DEL” the entire line (ie. the entire transaction).
Using the second 128 characters
CP437
In 1981 IBM released its first “IBM PC” which added to the ASCII code chart with “code page 437”. This used the 128 characters in the “second half” of the page to have useful graphical symbols, plus some commonly-used accented characters (useful in France and Spain, for instance).
Note that the first half is the same as the ASCII chart. To save space I won’t display the first half of the character set in future graphics.
The various graphical characters (lines, boxes, etc.) were drawn to the edge of the character position by the display card, so they could be combined seamlessly to make rudimentary menus, boxes, shadows, etc.
Notice also the inclusion of various accented characters, so that French, Spanish, and German could be rendered more accurately.
An example of a simple box made with CP437 characters:
Here is the same graphic with the spacing exaggerated to show the individual characters:
ISO-8859-1
When more computers could draw menus with bit-mapped graphics, the second 128 characters were re-purposed in various ways, depending on what language you were trying to render. For example:
This added more accented characters (and some control characters) at the expense of losing the graphical elements in CP437.
Control characters
Shown in the chart above in the first two rows are little-used “C0 and C1 control” characters. In their heyday they were used for special control over specialized hardware, such as setting a tab stop. These were non-printable characters which “controlled” the hardware, hence the name “control characters”.
Conceptually similar are well-known control characters like:
carriage-return (CR) — returns the “carriage” or screen cursor to column one
line-feed (LF) — feeds the paper or screen cursor forwards one line
form-feed (FF) — feeds the paper forwards to the next form or blanks the screen
backspace (BS) — moves the printer mechanism (or screen cursor) backwards one position
bell (BEL) — rings the printer’s bell (or sounds a beep on a terminal)
None of these “print” in the traditional sense, but they do have a useful purpose.
It is very common to mislabel text data with the charset label ISO-8859-1, even though the data is really Windows-1252 encoded. Many web browsers and e-mail clients will interpret ISO-8859-1 control codes as Windows-1252 characters, and that behavior was later standardized in HTML5, in order to accommodate such mislabeling and care should be taken to avoid generating these characters in ISO-8859-1 labeled content.
Windows-1252
This popular character set discards some of the control characters in ISO-8859-1 and replaces them with useful punctuation symbols like typographers’ quotes:
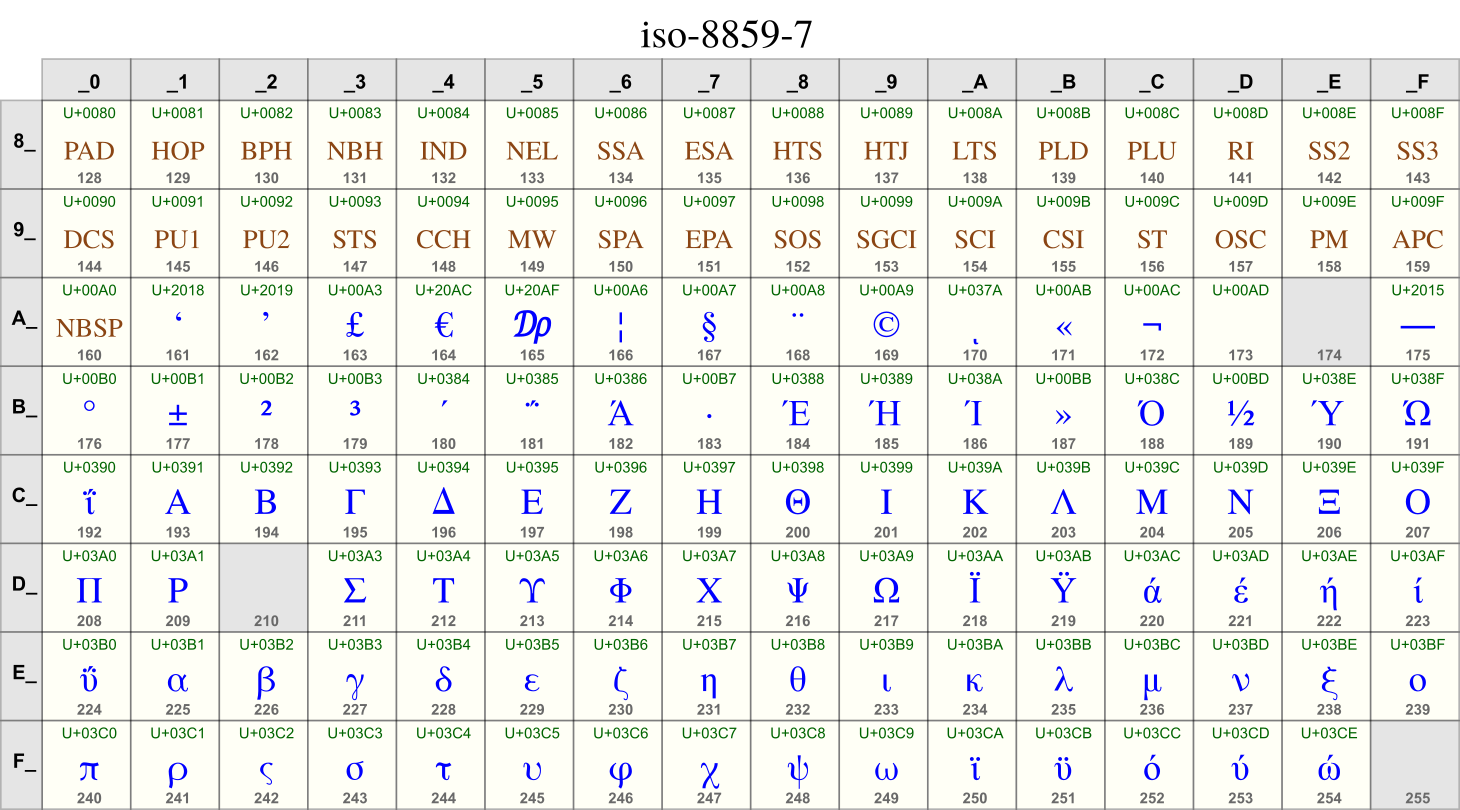
ISO-8859-7
This code page covers Latin and Greek letters.
Unicode
I could go on, but I’m probably starting to bore you. :)
It should be obvious from the above tables that a particular byte in a file could represent very different symbols (characters) on the computer screen. For example:
Here the character with a byte value of 206 (0xCE) in a file, or in memory, can be rendered in three completely different ways.
Problems with combining languages
Another problem is that if you wanted to have a web page (say) with Greek and Arabic characters it would be difficult or impossible, as you would have to switch code pages in the middle of the page.
Unique encoding for a character
This is where Unicode enters the picture. In response to the requirement for personal computers (such as Apple Macintosh and IBM PCs) to be able to be used world-wide, Unicode was developed in 1988. The idea of Unicode is to assign a “Unique code point” to every character and symbol, such that each has a unique position. For example, the Latin upper-case letter “A” is U+0041
By design, the first 256 codes were identical to ISO-8859-1 so as to make it trivial to convert existing western text. On the code charts on this page you can see the Unicode code point for each character shown. (U+xxxx where “xxxx” is a hexadecimal number).
The Unicode space was broken into blocks — where a block of codes would be reserved for use by a particular human language. Unicode characters also include punctuation, mathematical and musical symbols, emoji and so on.
Each code point has a name. For example U+0061 is named:
LATIN SMALL LETTER A
Names are unique, and once assigned cannot be changed.
Languages with many symbols
Languages such as Chinese and Japanese have many different characters (over 50,000) which makes it impossible to store them into a single byte. Hence some form of multi-byte representation was needed.
Fonts vs code points
Fonts
A font is a way of displaying a code point. There are thousands of fonts available for modern computers and printers.
For example, the lower-case Latin letter “a” (code point U+0061) could be displayed in various ways (using various fonts):
Notice the different fonts, text colours and sizes. However these are all the same Unicode code point (U+0061).
We can even rotate them on a curve, and they will still be the same code point:
Glyphs
A glyph is the name given to a “readable character”. That is, a symbol that we agree represents that particular letter.
Missing code points?
With tens of thousands of possible glyphs in Asian languages it is not possible for every font to have a rendering for every code point. Modern operating system font-handlers will substitute a glyph from a different font if it is not available in the primary (requested) font. For example, if you used Comic Sans to display a Chinese character, the operating system would find that the character is not available in Comic Sans, and find a different font that could display it (if possible).
If a suitable display glyph cannot be found (however the code point is valid) then although the Unicode specification does not mention a particular action, it is common for a small box to be displayed (U+25A1 named “WHITE SQUARE”).
This is humorously known as “Tofu” because of the similarity to the food of that name:
Some font handlers display the “Tofu” box with the underlying Unicode code point inside the box, in hex, in tiny characters. Thus it is possible to see exactly what character is missing. For example, for code points U+0D76 and U+0D77:
Glyph 0 must be assigned to a .notdef glyph. The .notdef glyph is very important for providing the user feedback that a glyph is not found in the font. This glyph should not be left without an outline as the user will only see what looks like a space if a glyph is missing and not be aware of the active font’s limitation.
It is recommended that the shape of the .notdef glyph be either an empty rectangle, a rectangle with a question mark inside of it, or a rectangle with an “X”. Creative shapes, like swirls or other symbols, may not be recognized by users as indicating that a glyph is missing from the font and is not being displayed at that location.
Google has made a “Noto” font family (available from Google Noto Fonts) which is supposed to avoid your seeing the “Tofu” symbol, hence the name “noto” (No Tofu). These are licensed under the SIL Open Font License (OFL).
If a code point is found to be invalid then you will see the “replacement character” glyph (U+FFFD named “REPLACEMENT CHARACTER”). This might happen if a particular character set attempts to display a character with no known mapping to a Unicode code point.
Encoding of a code-point
There are lots of ways of translating a Unicode code-point into a sequence of bytes for storing on disk or in memory. Let’s take a look at some of them.
7-bit ASCII
For simple text we can simply use the low-order byte and concatenate them together. For example:
Here we just put one byte after another, that is: 72,101,108,108,111
In other words in hexadecimal:
48 65 6C 6C 6F
Wide characters (UCS-2)
However things get tricker when we have a code-point which is greater than 0xFF. We need to store the results in multiple bytes. For example “Hello” in Greek:
One approach is to simply take two bytes for each code-point. In this case it could be:
Some computer hardware stores “words” (that is, sequences of bytes longer than one) with the most-significant byte first (big endian) and others with the least-significant byte first (little endian).
When Unicode code points are written to a disk file we need to be aware of which order they were written out in, because if you write a file on a big-endian computer, and then read it back in on a little-endian computer, the underlying numbers (code points) could look completely different.
Already we have the complexity of worrying if we put the high-order byte first (in each two-byte sequence) or the low-order byte.
If a file is saved to disk one approach is to add a byte order mark (BOM) (0xFEFF) to the start of the file. This is designed in such a way that it cannot be confused by the reader. For example:
FE FF 03 A7 03 B1 03 AF 03 C1 03 B5 03 C4 03 B5 (big endian)
^^^^^ BOM
FF FE A7 03 B1 03 AF 03 C1 03 B5 03 C4 03 B5 03 (little endian)
^^^^^ BOM
Big5
The Big5 encoding system was developed by a group of 5 big companies in Taiwan, Hong Kong, and Macau for Traditional Chinese characters. It is a double-byte encoding system (DBCS) however interleaved within it can be single bytes (ie. Latin characters). The “lead byte” has the high-order bit set to distinguish it from non-Chinese characters (such as a space).
First byte
Second byte
0x81 to 0xFE
0x40 to 0x7E and 0xA1 to 0xFE
A small example of the encoding from A840 to A8FF:
Notice that there doesn’t seem to be any linear relationship between the encoded value and the Unicode code point.
Double-byte vs wide-characters
Code points encoded in DBCS (double-byte encoding system) are not necessarily two bytes long. In the case of Big5 (and GBK below) one byte can be used for characters with code points from 0x00 to 0x7F. Thus Latin characters (like A to Z, 0 to 9, and punctuation) can be compactly stored in a single byte.
However for code points with higher values then the first byte (lead byte) indicates that we also need to consider the second byte, in order to interpret a single code point.
Similarly, UTF-8 can use from one to four bytes to encode a single code point.
On the other hand, Wide characters have a fixed width in memory or on disk. In the case of UCS-2 each character takes exactly 2 bytes (even if one of those is zero, which would be the case for low code points). This is less efficient in terms of disk or RAM usage, but easier to process, as you can step forwards or backwards one character with a simple arithmetic operation.
GBK
Another Chinese encoding system was developed in 1993 for mainland China.
GB abbreviates Guojia Biaozhun, which means national standard in Chinese, while K stands for Extension (“Kuozhan”).
It is conceptually similar to Big5 (there is a lead byte followed by another byte) however the two systems are not compatible.
Level
First byte
Second byte
Level GBK/1
0xA1 to 0xA9
0xA1 to 0xFE
Level GBK/2
0xB0 to 0xF7
0xA1 to 0xFE
Level GBK/3
0x81 to 0xA0
0x40 to 0xFE except 7F
Level GBK/4
0xAA to 0xFE
0x40 to 0xA0 except 7F
Level GBK/5
0xA8 to 0xA9
0x40 to 0xA0 except 7F
An example of GBK encoding is:
Problems with Big5 and GBK
Both GBK and Big5 have a problem — it is hard to “scan backwards”. For example, to find the last space in a line of text.
Since the second byte can have the low-order bit set you can’t tell (going backwards) if it stands alone as an ordinary ASCII character, or is part of a two-byte sequence.
UTF-8
UTF-8 is a multi-byte encoding system. It has the nice property that for ordinary ASCII (0x00 to 0x7F) it encodes identically to ASCII.
It has the other nice property that if you need multiple bytes, the second and subsequent bytes always have the high-order bit set, so you can “scan backwards” easily. A character always starts with:
0xxxxxxx; or
11xxxxxx
Subsequent bytes always are of the form:
10xxxxxx
Thus, a simple way of counting how many characters are in a string of bytes is to count all bytes that do not start with 10xxxxxx. (In these examples the letter “x” means don’t care — it can be a 0 or a 1).
This graphic shows the various ways that a series of code points can be encoded:
Transfer encoding
Another complexity can be seen in email messages. In order to keep mail messages “8 bit clean” (that is, keep the high-order bit as a zero, and also avoid the use of control characters in the middle of messages) they may be encoded as base64 or quoted-printable.
8-bit clean
Originally email messages could be read in ordinary text editors. However once people started sending images, sound files and movies, those attachments might have used all 256 possible characters in a byte. These could have been confused with email headers. Thus the motivation for using a reduced character set for attachments (or message bodies even).
Example email headers:
Content-Transfer-Encoding: base64
or
Content-Transfer-Encoding: quoted-printable
As an example:
Nick says “hello”.
Since the above uses “typographers quotes” it could be encoded as:
base64:
TmljayBzYXlzIJNoZWxsb5Qu
quoted-printable:
Nick says =93hello=94.
Base-64
Base-64 encoding converts a sequence of 3 bytes into 4 bytes. That is, 24 bits (3 bytes) become 32 bits (4 bytes). Base-64 encodes into only the following 64 characters:
In addition, if the source string is not exactly a multiple of 3 bytes in length then “=” characters are appended to the end to pad the string out.
Quoted-printable
This replaces characters not in the range 33 to 126 (0x21 to 0x7E) with the sequence =xx where “xx” is the character code in hex. For example, =20 would be a space. Also, naturally, the “=” character itself must be encoded as =3D.
In addition, lines are kept to no more than 76 characters. If a line break has to be inserted, which was not in the original text, then the line ends with the “=” character (which is then discarded when decoding).
Other related topics
Conversion between character sets
Windows
The function WideCharToMultiByte can be used to convert from “wide characters” (that is, 2-byte code points) into “multi-byte” characters, for example UTF-8.
The inverse operation can be carried out by the function MultiByteToWideChar.
Unix
The program “iconv” (and also the function iconv for use in C) can be used to translate from and to various character sets. Example of command-line usage:
It was very expensive to make. Judging by the photo we are looking at 64 × 16-bit bytes there — a total of 1024 bits. A close-up view of part of it:
Each “magnetic core” (the black ring) was one bit. They were addressed in the X and Y direction (the horizontal and vertical wires). To read a bit the hardware attempted to change a bit from 1 to 0 which would generate a pulse in the third wire which runs diagonally through all the bits. If the third wire received a pulse then the hardware knew that the bit had changed, meaning it was previously a 1-bit. Then, of course, it had to set that bit back to 1 ready for next time it was to be read. This was a slow process.
These had to be assembled by hand.
Unicode code points inside HTML documents
An HTML document which does not directly have Unicode encoding (for example ISO-8859-1) can embed Unicode code points by using the HTML entity syntax:
’ (where 8217 is the code point in decimal)
’ (where 2019 is the (same) code point in hexadecimal)
For example:
We’re excited --> We’re excited
Drum printers
Here is a photo of an old “line” printer. It printed a line at a time on continuously-fed paper:
Image credit: Dave Fischer.
All of the letters and symbols needed to be printed are engraved on a large metal drum. This drum rotated very rapidly, and printed by the action of hammers which struck the paper passing through the printer (through an ink ribbon) at the exact correct moment. The drum was large enough as it was without trying to place lower-case letters on it.
Hence computer output was all in upper-case for quite a few years, until printers which were pixel addressable (such as inkjet, dot-matrix and laser printers) were developed.
Conclusion
The various character sets invented over the years are rich grounds for confusion. Thankfully these days UTF-8 is gaining increasing popularity. Its advantages are:
Reasonably compact, especially for Latin encodings (can be as short as a single byte per character)
Can encode the entire Unicode range of code points
Is supported in most modern email clients, web browsers, and text editors
Other character sets can be easily converted to UTF-8.
When reading a file it is important to know the character encoding. If you think it is UTF-8 and it is really Windows-1252 (or vice-versa) then some characters will not be display or printed correctly.